AI PC的竞争,越来越火热了!
就连数据中心收入占比达到四分之三的英伟达,也用消费级的AI PC显卡领跑这场战斗。
换言之,老黄在做工业级“核弹”的同时,在RTX这样的消费级产品中,也要全力发展AI运算。

而且规模还不小,据介绍,RTX AI PC目前已成为拥有超过1亿用户和500款AI应用和游戏的生态。
在RTX AI PC的一场技术品鉴会中,量子位也体验到了英伟达AI算力在消费级显卡上的应用。
更高效地利用算力,需要软硬件配合
古语有云,“工欲善其事,必先利其器”,对于AI创作者而言,选择高性能的运算设备是无比重要的。
当然了,也并不是说就要直接上专业卡,对于单纯的创作来说,消费级的显卡已经足够。
吐司是一家大型在线生图的AI模型社区,提供了包括超16w+的模型 在内的AI 模型资源。
最近,吐司使用第三方测试软件UL Procyon AI基准,完整测试了英伟达RTX 40系列多款型号的显卡和笔记本电脑的生图能力。

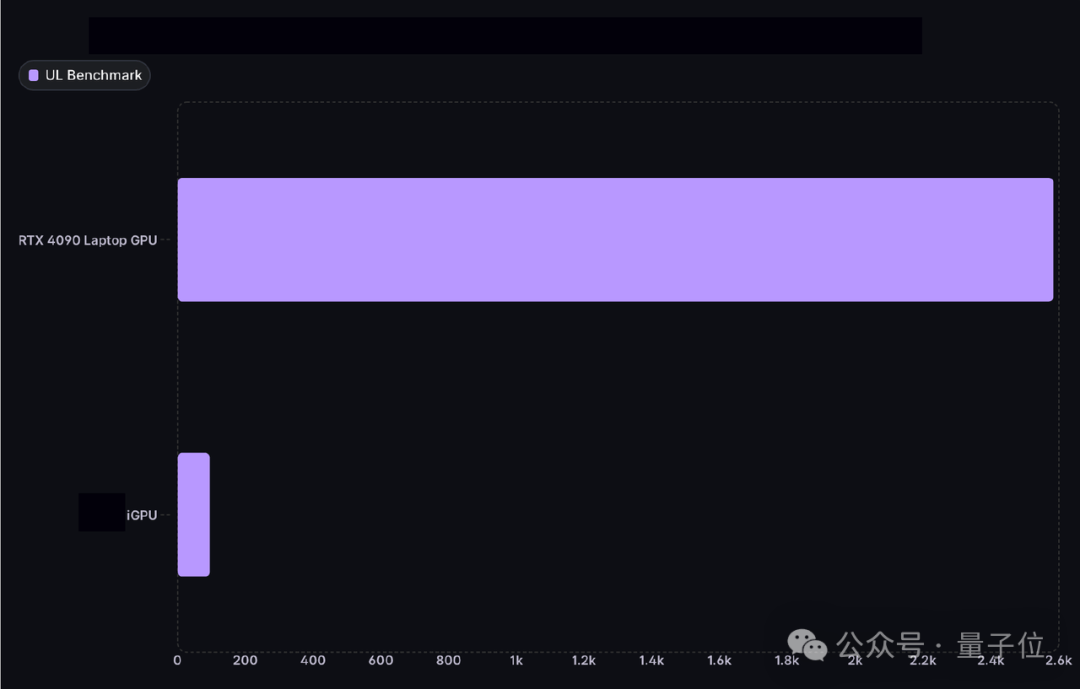
相比于集成显卡,在同时开启两个厂商加速框架的情况下,笔记本版的4090在运行SD 1.5的UL Benchmark时,性能超出了27倍。
但做AI运算,单靠硬件性能是不够的,软件程序需要针对硬件特征做专门的优化,才能更高效地利用硬件资源,用相同的配置实现更高的推理速度。
比如英伟达的Tensor RT(简称TRT)加速框架,就起到了让模型更好适配显卡中的Tensor Core,从而实现更高运算性能的作用。
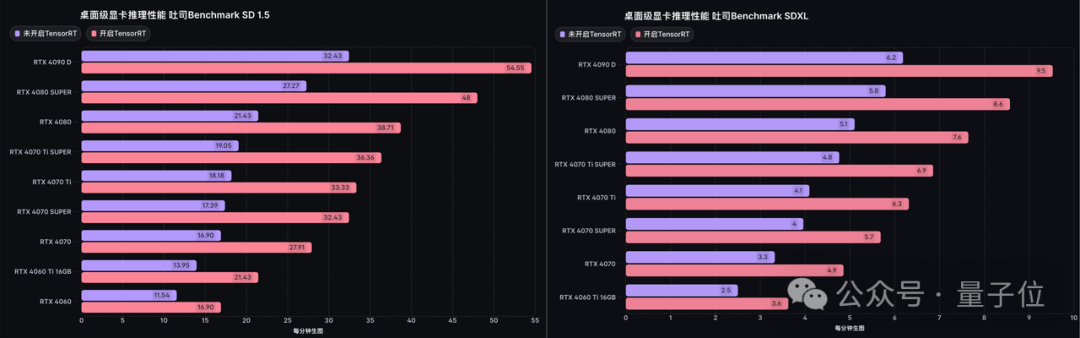
同样在吐司的测试当中,对于RTX 40系列的各种显卡,开启TRT前后,无论是运行SD1.5还是SDXL,每分钟生成图片的数量均有显著提升,其中4090D的SD 1.5生成速度达到了每秒54.55张图。
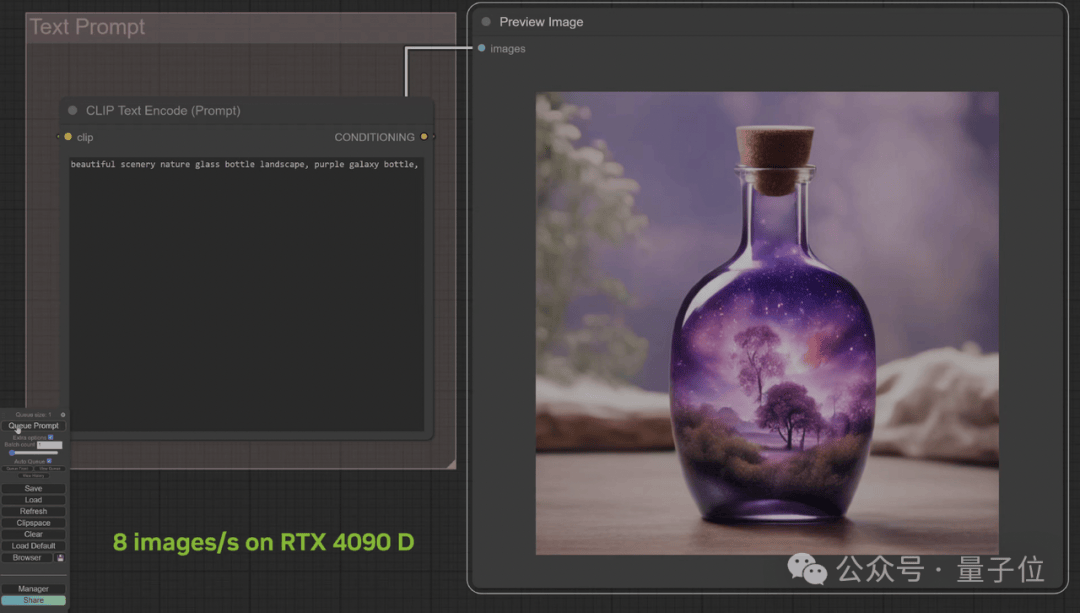
而如果改用StreamDiffusion,同时忽略硬盘读写带来的降速,在4090D上开启TRT,最快可达到每秒128张图。

在实际环境中,这个速度会被硬盘拖慢,最终的速度大约是每秒八张,但TRT依然是当下最快的Stable Diffusion加速方式。
不过需要说明的是,对于内容生成而言,单纯速度快并不等于直接的生产力提升。
那么,这样的速度优势又该如何利用起来呢?
速度不能直接变成生产力,还要与工作特点结合
要想把生成速度变为生产力,关键不仅在于技术,更在于与行业工作特点的充分结合。
比如在建筑行业,即致AI就基于扩散模型和蒸馏技术,通过RTX 4090 D GPU的加速,实现了秒级的AI实时绘画,实时将手绘草稿绘制成建筑效果图。

艾哎集瑟科技联合创始人、前沿建筑设计师言萧表示:
作为一名经常使用AI工具的建筑师,我对RTX平台的加速优势深有体会。
它极大提高了AI图形生成软件,特别是Stable Diffusion等工具的性能,在建筑设计的方案概念阶段尤为重要。
这种技术进步不仅提升了设计效率,也为建筑师提供更广阔的创作空间。
数字艺术家、策展人土豆人tudou_man是许多知名品牌的合作艺术家。他以将新锐的艺术方式,与AIGC技术极其自然的交融在一起,创作出了许多经典作品。
比如他用AI创造的麦当劳“传家宝”系列作品就曾在网络上刷屏,还获得了官方的转发。

他本人表示,RTX 40系列AI PC平台带来的运算加持,让人震惊之余,RTX平台为数字艺术家提供高效的AI算力加速。
AbleSlide联合创始人Blender艺术家AI创作者、Blender 艺术家、AI创作者Simon阿文,参与了今年春晚中AI视频的创作。
他还用AI创作了《花中维纳斯》系列作品,展现了一场视觉交响曲,通过AI的力量,静态图像被转化为一种动态体验,用自然的镜头见证了维纳斯的重生。


