自从各大模型厂商开始以 0.1 的小版本更新模型后,模型更新的频率越来越快了,3 月 5 日,就在 GPT-5.3 Instant 刚更新完毕后两天,GPT-5.4 也来了。
这款模型被 OpenAI 定位为“面向专业工作的最强前沿模型”。它以 GPT-5.4 Thinking 的形式进入 ChatGPT,同时上线 API 和代码开发平台 Codex。此外还有一个 GPT-5.4 Pro 版本,面向需要极致复杂任务性能的用户,仅对 ChatGPT Pro(月费 200 美元)和 Enterprise 订阅者开放。Plus 用户可以使用 GPT-5.4 Thinking,免费用户则只能在系统自动路由时偶尔被分配到该模型。

(来源:OpenAI)
GPT-5.4 在 API 和 Codex 中支持最高 100 万 token(标记)的上下文窗口(Context Window,即模型单次处理文本的长度上限),这是目前 OpenAI 提供的最大上下文窗口。不过超过 272,000 token 的请求,输入价格翻倍、输出加收 50%。标准输入单价从 GPT-5.2 时代的每百万 token 1.75 美元涨到了 2.50 美元,涨幅 43%。
OpenAI 给出的解释是,模型能力更强,研究投入更大,同时推理效率更高——用更少的 token 解决同样的问题,所以总成本未必上升。作为参考,Anthropic 的 Claude Opus 4.6 输入价格是每百万 token 5 美元,输出 25 美元,GPT-5.4 Pro 的定价实际上还要更贵。

(来源:OpenAI)
跑分方面,在 OSWorld-Verified 基准测试中,GPT-5.4 的成功率达到 75.0%,远超 GPT-5.2 的 47.3%,也超过了该测试报告的人类表现 72.4%。在 OpenAI 的官方演示中,通过 Playwright Interactive(一种浏览器自动化工具)与图像生成结合,仅凭单条提示词就构建出了一个主题乐园模拟游戏,涵盖瓦片路径布置、游乐设施建造、游客路径寻路和实时公园指标。
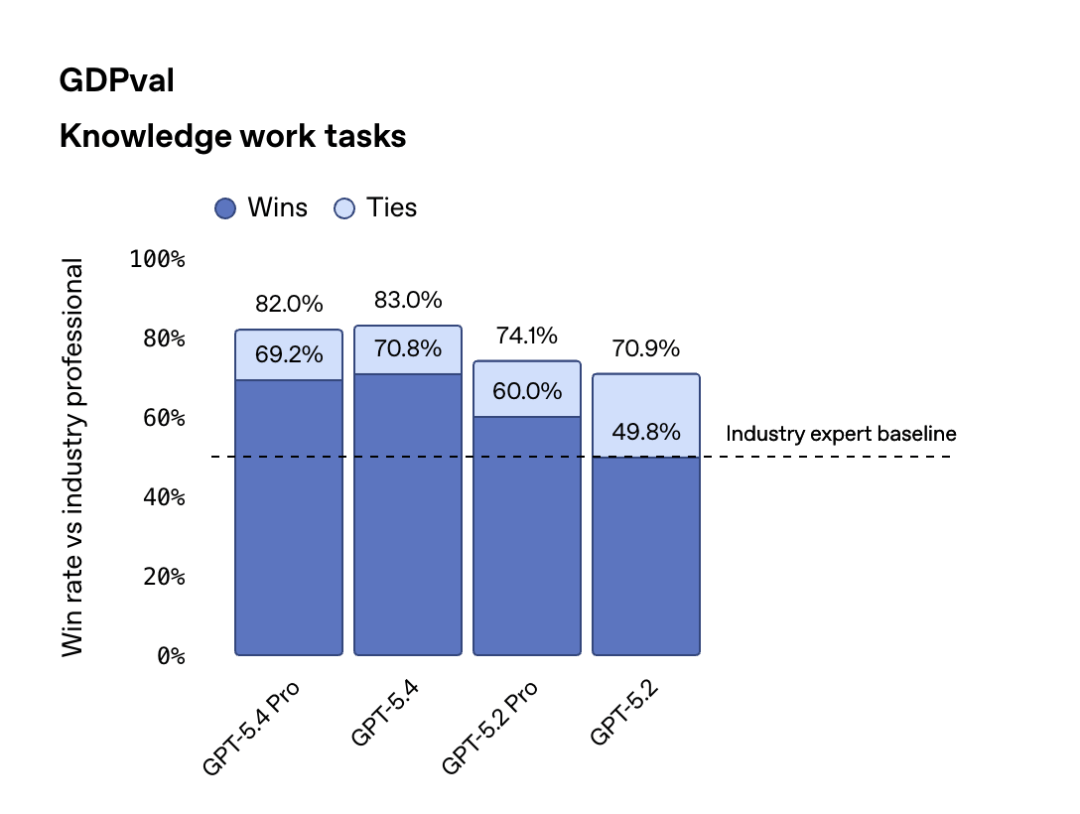
在 BrowseComp(衡量 AI 代理在网页上持续检索难以定位信息的能力)上,GPT-5.4 比 GPT-5.2 提升了 17 个百分点,Pro 版本达到 89.3%。OpenAI 自己的 GDPval 测试(覆盖美国 GDP 贡献最大的 9 个行业、44 种职业的知识工作任务)给出了 83% 的得分,意味着在这些任务上模型的表现达到或超过了行业从业者水平。
在电子表格建模任务中,得分从 GPT-5.2 的 68.4% 跳到了 87.3%;人类评审者在 68% 的情况下更偏好 GPT-5.4 生成的演示文稿。
(来源:OpenAI)
这些数字背后有一个关键能力:原生计算机使用(Native Computer Use)。GPT-5.4 是 OpenAI 发布的第一个内置原生计算机操控能力的通用模型,可以通过编写代码(比如使用 Playwright 库)来操控计算机,也可以直接根据屏幕截图发出鼠标和键盘指令。这让它能够在软件环境中执行“构建 - 运行 - 验证 - 修复”的循环,完成需要跨多个应用的多步骤工作流。
另一个对开发者影响较大的新特性是 Tool Search(工具搜索)。过去,在 API 中使用工具时,所有工具的定义需要一次性塞进提示词里,随着工具越来越多,这造成了巨大的 token 开销和上下文污染。GPT-5.4 引入了一个结构性的优化:模型只接收一个轻量级工具列表,需要用到某个工具时再动态检索其完整定义。
在 Scale 公司的 MCP Atlas 基准测试中,使用 36 个 MCP 服务器执行 250 项任务,工具搜索将 token 消耗降低了 47%,同时保持了准确率。对于构建大型智能体(Agent)系统的开发者来说,这直接意味着更低的成本和更快的响应。
幻觉(Hallucination,即模型编造事实)的改善也被重点提及。OpenAI 表示,GPT-5.4 在单条声明中出错的概率比 GPT-5.2 降低了 33%,整体回复包含错误的概率降低了 18%。
不过需要注意的是,在 HealthBench 医疗健康评测中,GPT-5.4 的得分是 62.6%,反而略低于 GPT-5.2 的 63.3%。模型回复的平均长度也更长了,从 GPT-5.2 的 2,676 字符增加到 3,311 字符。更长的回复有时候意味着更全面,也有时候意味着更啰嗦,用户体验如何还有待观察。
在抽象推理方面,进步幅度较为显著。ARC-AGI-2 从 52.9% 跃升至 73.3%,Pro 版本达到 83.3%。FrontierMath Tier 4(最高难度的数学推理测试)从 18.8% 提升至 27.1%,Pro 版本为 38.0%。
一些拿到早期测试权限的用户已经在 X 上密集发布体验报告。AI 创业者 Matt Shumer 称自己测试 GPT-5.4 长达一周,认为其标准版配合深度思考模式的表现已经超过了此前其他模型的 Pro 版本,以至于他几乎不再需要切换到 Pro 模式。
(来源:X)
其编码能力尤其突出,Shumer 称在 Codex 中使用 GPT-5.4 的可靠性极高,编码问题“基本上已经被解决了”。Pro 版本则能攻克其他模型完全无法处理的难题,但对日常任务来说属于“过剩 火力”。而且的确和 OpenAI 官方宣称的一样,其标准思考版本使用的推理 token 比以前更少,响应速度明显加快。
不过 Shumer 也指出了几个短板:前端设计品味远不如 Claude Opus 4.6 和 Gemini 3.1 Pro;模型有时候会忽略显而易见的现实世界语境,比如为他规划旅行行程时选了一堆春假期间会被游客挤爆的地点。在 OpenClaw 中测试 GPT-5.4 时,模型经常在任务完成之前就停下来。
OpenAI 同时宣布了一套面向金融行业的企业产品,核心是 ChatGPT for Excel 和 Google Sheets(测试版)。OpenAI 将其描述为 ChatGPT 直接嵌入电子表格,用于构建、分析和更新复杂的财务模型。
配套的还有与 FactSet、MSCI、Moody's 等金融数据提供商的集成,以及可复用的“Skills”(技能模板),用于盈利预览、可比公司分析、DCF(折现现金流)分析等标准化金融工作。
在 OpenAI 内部的投资银行基准测试中,GPT-5.4 Thinking 的表现从 GPT-5 时代的 43.7% 提升到了 88.0%。这组产品的对手毫无疑问是 Anthropic 刚推出的 Cowork 桌面工具和 Claude 的文件管理能力,以及 Google 在 Workspace 中持续深入的 AI 集成。
综合来看,GPT-5.4 称得上是一种在多个维度上的整合性进步。原生计算机操控、工具搜索、更大的上下文窗口、更强的推理能力,这些合在一起构成了一个更完整的“AI 工作助手”,也为 OpenClaw 这类智能体框架提供了更强的底层引擎。
日常聊天和写邮件的改进可能体现在细节上,真正能感受到跨代差异的,是那些用 AI 做 PPT、建财务模型、在 Codex 里跑自动化流程的重度用户,以及正在把 OpenClaw 当成个人数字助手的那批早期采纳者。

